DataMaker¶
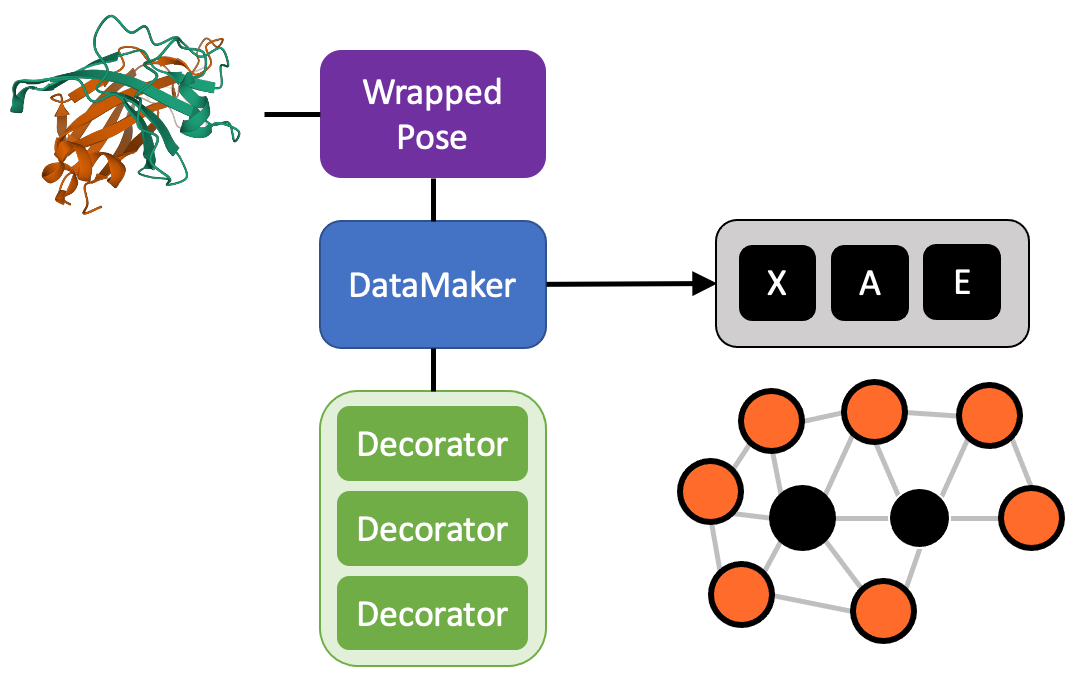
The DataMaker is the main character of Menten GCN. It has the job of applying decorators to poses and organizing them as tensors.
-
class
menten_gcn.DataMaker(decorators: List[menten_gcn.decorators.base.Decorator], edge_distance_cutoff_A: float, max_residues: int, exclude_bbdec: bool = False, nbr_distance_cutoff_A: Optional[float] = None, dtype: numpy.dtype = <class 'numpy.float32'>)[source]¶ The DataMaker is the user’s interface for controlling the size and composition of their graph.
- Parameters
decorators (list) – List of decorators that you want to include
edge_distance_cutoff_A (float) – An edge will be created between any two pairs of residues if their C-alpha atoms are within this distance (measured in Angstroms)
max_residues (int) – What is the maximum number of nodes a graph can have? This includes focus and neighbor nodes. If the number of focus+neighbors exceeds this number, we will leave out the neighbors that are farthest away in 3D space.
exclude_bbdec (bool) – Every DataMaker has a standard “bare bones” decorator that is prepended to the list of decorators you provide. Set this to false to remove it entirely.
nbr_distance_cutoff_A (float) – A node will be included in the graph if it is within this distance (Angstroms) of any focus node. A value of None will set this equal to edge_distance_cutoff_A
dtype (np.dtype) – What numpy data type should we use to represent your data?
-
summary()[source]¶ Print a summary of the graph decorations to console. The goal of this summary is to describe every feature with enough detail to be able to be reproduced externally. This will also print any relevant citation information for individual decorators.
import menten_gcn as mg import menten_gcn.decorators as decs decorators=[ decs.SimpleBBGeometry(), decs.Sequence() ] data_maker = mg.DataMaker( decorators=decorators, edge_distance_cutoff_A=10.0, max_residues=15 ) data_maker.summary()
Summary: 23 Node Features: 1 : 1 if the node is a focus residue, 0 otherwise 2 : Phi of the given residue, measured in radians. Spans from -pi to pi 3 : Psi of the given residue, measured in radians. Spans from -pi to pi 4 : 1 if residue is A, 0 otherwise 5 : 1 if residue is C, 0 otherwise 6 : 1 if residue is D, 0 otherwise 7 : 1 if residue is E, 0 otherwise 8 : 1 if residue is F, 0 otherwise 9 : 1 if residue is G, 0 otherwise 10 : 1 if residue is H, 0 otherwise 11 : 1 if residue is I, 0 otherwise 12 : 1 if residue is K, 0 otherwise 13 : 1 if residue is L, 0 otherwise 14 : 1 if residue is M, 0 otherwise 15 : 1 if residue is N, 0 otherwise 16 : 1 if residue is P, 0 otherwise 17 : 1 if residue is Q, 0 otherwise 18 : 1 if residue is R, 0 otherwise 19 : 1 if residue is S, 0 otherwise 20 : 1 if residue is T, 0 otherwise 21 : 1 if residue is V, 0 otherwise 22 : 1 if residue is W, 0 otherwise 23 : 1 if residue is Y, 0 otherwise 2 Edge Features: 1 : 1.0 if the two residues are polymer-bonded, 0.0 otherwise 2 : Euclidean distance between the two CB atoms of each residue, measured in Angstroms. In the case of GLY, use an estimate of ALA's CB position
-
get_N_F_S() → Tuple[int, int, int][source]¶ - Returns
N (int) – Maximum number of nodes in the graph
F (int) – Number of features for each node
S (int) – Number of features for each edge
-
generate_input_for_resid(wrapped_pose: menten_gcn.wrappers.WrappedPose, resid: int, data_cache: Optional[menten_gcn.data_management.DecoratorDataCache] = None, sparse: bool = False, legal_nbrs: Optional[List[int]] = None) → Tuple[numpy.ndarray, numpy.ndarray, numpy.ndarray, List[int]][source]¶ Only have 1 focus resid? Then this is sliiiiiiightly cleaner than generate_input(). It’s completely debatable if this is even worthwhile
- Parameters
wrapped_pose (WrappedPose) – Pose to generate data from
focus_resid (int) – Which resid is the focus residue? We use Rosetta conventions here, so the first residue is resid #1, second is #2, and so one. No skips.
data_cache (DecoratorDataCache) – See make_data_cache for details. It is very important that this cache was created from this pose
legal_nbrs (list of ints) – Which resids are allowed to be neighbors? All resids are legal if this is None
- Returns
X (ndarray) – Node Features
A (ndarray) – Adjacency Matrix
E (ndarray) – Edge Feature
sparse (bool) – This setting will use sparse representations of A and E. X will still have dimension (N,F) but A will now be a scipy.sparse_matrix and E will have dimension (M,S) where M is the number of edges
meta (list of int) – Metadata. At the moment this is just a list of resids in the same order as they are listed in X, A, and E
-
generate_input(wrapped_pose: menten_gcn.wrappers.WrappedPose, focus_resids: List[int], data_cache: Optional[menten_gcn.data_management.DecoratorDataCache] = None, sparse: bool = False, legal_nbrs: Optional[List[int]] = None) → Tuple[numpy.ndarray, numpy.ndarray, numpy.ndarray, List[int]][source]¶ This is does the work of creating a graph and representing it as tensors
- Parameters
wrapped_pose (WrappedPose) – Pose to generate data from
focus_resids (list of ints) – Which resids are the focus residues? We use Rosetta conventions here, so the first residue is resid #1, second is #2, and so one. No skips.
data_cache (DecoratorDataCache) – See make_data_cache for details. It is very important that this cache was created from this pose
sparse (bool) – This setting will use sparse representations of A and E. X will still have dimension (N,F) but A will now be a scipy.sparse_matrix and E will have dimension (M,S) where M is the number of edges
legal_nbrs (list of ints) – Which resids are allowed to be neighbors? All resids are legal if this is None
- Returns
X (ndarray) – Node Features
A (ndarray) – Adjacency Matrix
E (ndarray) – Edge Feature
meta (list of int) – Metadata. At the moment this is just a list of resids in the same order as they are listed in X, A, and E
-
generate_XAE_input_tensors(sparse: bool = False) → Tuple[tensorflow.python.keras.engine.base_layer.Layer, tensorflow.python.keras.engine.base_layer.Layer, tensorflow.python.keras.engine.base_layer.Layer][source]¶ This is just a safe way to create the input layers for your keras model with confidence that they are the right shape
- Parameters
sparse (bool) – If true, returns shapes that work with Spektral’s disjoint mode. Otherwise we align with Spektral’s batch mode.
- Returns
X_in (Layer) – Node Feature Input
A_in (Layer) – Adjacency Matrix Input
E_in (Layer) – Edge Feature Input
I_in (Layer) – Batch Index Input (sparse mode only)
-
make_data_cache(wrapped_pose: menten_gcn.wrappers.WrappedPose) → menten_gcn.data_management.DecoratorDataCache[source]¶ Data caches save time by re-using tensors for nodes and edges you have aleady calculated. This usually gives me a 5-10x speedup but your mileage may vary.
- Parameters
wrapped_pose (WrappedPose) – Each pose needs a different cache. Please give us the pose that corresponds to this cache
- Returns
cache (DecoratorDataCache) – A data cache that can be passed to generate_input and generate_input_for_resid.